- Wie behebe ich gesendete URLs, die von Robots txt blockiert werden??
- Wie entsperre ich Robots-txt?
- Was bedeutet blockiert durch robots txt??
- Benötigt meine Website eine Robots-txt-Datei??
- Wie überprüfen Sie, ob robots txt funktioniert??
- Wie aktiviere ich Robots-txt?
- Was ist Robot-txt in SEO??
- Respektiert Google Robots-txt?
- Wie stelle ich sicher, dass Google nicht blockiert wird??
- Kann Google ohne Robots-txt crawlen??
- Wie deaktiviere ich die Subdomain in robots txt?
- Wie blockiere ich einen Crawler in Robots txt?
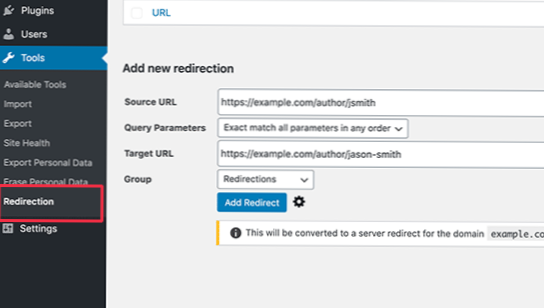
Wie behebe ich gesendete URLs, die von Robots txt blockiert werden??
Aktualisieren Sie Ihre Roboter.
txt-Datei, indem Sie die Regel entfernen oder bearbeiten. Normalerweise befindet sich die Datei unter http://www.[IhrDomainname].com/roboter.txt können sie jedoch überall in Ihrer Domain existieren exist. Die Roboter. txt Tester-Tool kann Ihnen helfen, Ihre Datei zu finden.
Wie entsperre ich Robots-txt?
Gehen Sie wie folgt vor, um Suchmaschinen für die Indexierung Ihrer Website zu entsperren:
- Melden Sie sich bei WordPress an.
- Gehen Sie zu Einstellungen → Lesen.
- Scrollen Sie auf der Seite nach unten, bis dort "Suchmaschinensichtbarkeit" steht
- Deaktivieren Sie das Kontrollkästchen neben "Suchmaschinen davon abhalten, diese Website zu indizieren"
- Klicken Sie unten auf die Schaltfläche "Änderungen speichern".
Was bedeutet blockiert durch robots txt??
Wenn Ihre Webseite von einem Roboter blockiert wird. txt-Datei, kann es immer noch in den Suchergebnissen erscheinen, aber das Suchergebnis hat keine Beschreibung und sieht in etwa so aus. Bilddateien, Videodateien, PDFs und andere Nicht-HTML-Dateien werden ausgeschlossen.
Benötigt meine Website eine Robots-txt-Datei??
Die meisten Websites brauchen keine Roboter. txt-Datei. Das liegt daran, dass Google normalerweise alle wichtigen Seiten Ihrer Website finden und indizieren kann. Und sie indexieren automatisch KEINE Seiten, die nicht wichtig sind, oder duplizieren Versionen anderer Seiten.
Wie überprüfen Sie, ob robots txt funktioniert??
Testen Sie Ihre Roboter. txt-Datei
- Öffnen Sie das Tester-Tool für Ihre Site und scrollen Sie durch die Robots. ...
- Geben Sie die URL einer Seite Ihrer Website in das Textfeld unten auf der Seite ein.
- Wählen Sie in der Dropdown-Liste rechts neben dem Textfeld den Benutzeragenten aus, den Sie simulieren möchten.
- Klicken Sie auf die Schaltfläche TEST, um den Zugriff zu testen.
Wie aktiviere ich Robots-txt?
Geben Sie einfach Ihre Root-Domain ein und fügen Sie dann /robots . hinzu. txt an das Ende der URL. Zum Beispiel befindet sich die robots-Datei von Moz unter moz.com/roboter.TXT.
Was ist Robot-txt in SEO??
Die Roboter. txt-Datei, auch bekannt als Robots Exclusion Protocol oder Standard, ist eine Textdatei, die Web-Robots (meist Suchmaschinen) mitteilt, welche Seiten Ihrer Website gecrawlt werden sollen. Es teilt Web-Robots auch mit, welche Seiten nicht gecrawlt werden sollen.
Respektiert Google Robots-txt?
Google hat offiziell angekündigt, dass der GoogleBot keinem Roboter mehr gehorchen wird. txt-Anweisung im Zusammenhang mit der Indexierung. Verlage, die sich auf die Roboter verlassen. txt-noindex-Direktive hat bis zum 1. September 2019 Zeit, sie zu entfernen und eine Alternative zu verwenden.
Wie stelle ich sicher, dass Google nicht blockiert wird??
Erstellen Sie ein Meta-Tag
Hier sind einige gängige Meta-Tags, die Sie zu Ihren HTML-Seiten hinzufügen können: Verhindern Sie, dass bestimmte Artikel auf Ihrer Website in Google News erscheinen, blockieren Sie den Zugriff auf Googlebot-News mit dem folgenden Meta-Tag: <meta name="Googlebot-News" content="noindex, nofollow">.
Kann Google ohne Robots-txt crawlen??
txt-Datei existiert nicht. Das bedeutet, dass Crawler in der Regel davon ausgehen, dass sie alle URLs der Website crawlen können. Um das Crawlen der Website zu blockieren, werden die Robots.
Wie deaktiviere ich die Subdomain in robots txt?
Ja, Sie können eine ganze Subdomain über Robots blockieren. txt, aber Sie müssen einen Roboter erstellen. txt-Datei und platzieren Sie sie im Stammverzeichnis der Subdomain, und fügen Sie dann den Code hinzu, um die Bots anzuweisen, sich vom Inhalt der gesamten Subdomain fernzuhalten.
Wie blockiere ich einen Crawler in Robots txt?
Wenn Sie verhindern möchten, dass der Google-Bot in einem bestimmten Ordner Ihrer Website crawlt, können Sie diesen Befehl in die Datei einfügen:
- User-Agent: Googlebot. Verbieten: /example-subfolder/ User-Agent: Googlebot Verbieten: /example-subfolder/
- User-Agent: Bingbot. Nicht zulassen: /example-subfolder/blocked-page. html. ...
- User-Agent: * Verbieten: /